Well, to answer my own question, you want Netflix, Hulu, etc. to use compression when you stream movies or TV shows. Or compress files to free up disk space. There are a variety of reasons to use compression.
I’ve been doing a lot of testing using large files and it got me thinking about the disk I/O (Input/Output), throughput and overall performance of messages traveling through a queue manager.
There is a lot going on under the covers in a queue manager as it relates to disk I/O. There are queue buffers for each queue, queue files (aka queue backing files) and of course, the recovery log files.
Each queue in the queue manager is assigned two buffers to hold messages (one for persistent messages and one for non-persistent messages). The persistent queue buffer size is specified using the tuning parameter DefaultPQBufferSize. The non-persistent queue buffer size is specified using the tuning parameter DefaultQBufferSize.
- DefaultPQBufferSize has a default value of 128KB for 32-bit Queue Managers and 256KB for 64-bit Queue Managers.
- DefaultQBufferSize has a default value of 64KB for 32-bit Queue Managers and 128KB for 64-bit Queue Managers.
Note: You can read the MQ Knowledge Center to learn how to change these values (it’s a little complicated).
Here’s the process of the queue manager handling an application putting a message to a queue:
- The message will be put into the buffer of the waiting application if it can fit.
- If that fails, the queue manager tries to write the message to the queue buffer, if it can fit.
- Otherwise, it is written to the queue file.
When the consumer (non-waiting) gets a message from a queue, the queue manager will retrieve it from the queue buffer, if available, otherwise from the queue file. If the consumer was waiting for a message then the queue manager will attempt to write it directly to the applications buffer. In theory, it is all about performance.
If you ever went to MQ Technical Conference (MQTC), you may have attended one of Chris Frank’s excellent sessions (he’s an IBMer) on queue manager logging. Here is a screen-shot from Chris Frank’s MQTC 2016 More Mysteries of the MQ Logger (page 9) that provides a high-level view of disk I/O.
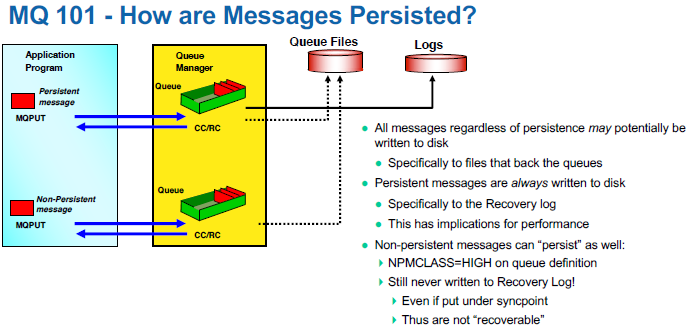
In the picture, the solid line shows the queue manager writing the messages to the recovery log files. The dotted lines means that the message may or may not be written to the queue file. See the above for the scenarios of when/why the queue manager would write a message to the queue file.
Here’s an example for a 64-bit queue manager:
- If your persistent message size is 10KB that means the queue buffer can hold a maximum of 25 messages.
- If your non-persistent message size is 10KB that means the queue buffer can hold a maximum of 10 messages.
That’s all well and good, if the message size is small but what about 300KB or 2MB message sizes? They do not fit in the queue buffers (persistent nor non-persistent). What if a number of applications send messages between 5MB and 20MB (without a consumer waiting to get it)? Unless the MQAdmin has drastically increased the DefaultPQBufferSize and DefaultQBufferSize parameters, then the messages will always be written to the queue file.
So, lets take a moment to think about large, say 10MB, persistent messages and the DefaultPQBufferSize parameter is set at its default value with no consumers waiting to receive the message. First, the queue manager writes the message to the recovery log file and then it will write it to queue file. When the consumer finally performs a get, the queue manager will need to read the message from the queue file. What if your application is sending thousands of 10MB messages per day. The amount of disk I/O is huge. i.e. 2 writes of 10MB and 1 read of 10MB per message.
Question: Would you trade a little CPU time to drastically reduce the disk I/O time?
I had the bright idea of using lossless compression to help speed things up. So, I created a new product called MQ Message Compression (MQMC). MQMC is an MQ API Exit. My thought was if you can reduce (compress) a message by a factor of 3 or 4 (sometimes far, far more), then there would be much less disk I/O which would speed up the whole throughput of the message.
The MQMC supports the following 8 lossless compression algorithms:
- LZ1 (aka LZ77) – I used Andy Herbert’s modified version with a pointer length bit-width of 5.
- LZ4 – It is promoted as extremely fast (which it is).
- LZW – I used Michael Dipperstein’s implementation of Lempel-Ziv-Welch.
- LZMA Fast – I used the LZMA SDK from 7-Zip with a Level set to 4.
- LZMA Best – I used the LZMA SDK from 7-Zip with a Level set to 5.
- RLE – Run Length Encoding – I wrote the code from pseudo code – very basic stuff.
- ZLIB Fast – I used Rich Geldreich’s miniz implementation of ZLIB with a Level of Z_BEST_SPEED.
- ZLIB Best – I used Rich Geldreich’s miniz implementation of ZLIB with a Level of Z_BEST_COMPRESSION.
So, how do you know what is the best compression algorithm for the end-user’s data? Well, to take the guess work out of it, I wrote a simple program called TESTCMPRSN. It applies all 8 compression algorithms against a file and display the results.
The important thing to remember is that disk I/O reads or writes are substantially slower than CPU processing.
Here’s an example of TESTCMPRSN program being run against a 9.17MB XML file (really large file):
~/test> ./testcmprsn very_lrg_msg.xml
testcmprsn version 0.0.1 (Linux64) {Sep 3 2020}
very_lrg_msg.xml size is 9614354 (9.17MB)
Time taken to perform memcpy() is 4.8770ms
Algorithm Compressed Compression Compression Decompression
Size Time in ms Ratio Time in ms
LZ1 924233 (902.57KB) 915.9610 10.40 to 1 13.9510
LZ4 112253 (109.62KB) 3.4830 85.65 to 1 2.9540
LZMA Fast 32872 (32.10KB) 108.4230 292.48 to 1 11.0730
LZMA Best 27675 (27.03KB) 1152.6960 347.40 to 1 10.6730
LZW 287184 (280.45KB) 203.0840 33.48 to 1 80.8820
RLE 13213500 (12.60MB) 28.1200 0.73 to 1 26.2680
ZLIB Fast 240612 (234.97KB) 28.3140 39.96 to 1 11.2530
ZLIB Best 83375 (81.42KB) 88.5010 115.31 to 1 8.4590
testcmprsn is ending.
Clearly, LZMA Best crushed it. It reduced a 9.17MB file to just 27.03KB (347 fold reduction) but at a cost of 1152.696 milliseconds. A better option for that type of data is to use LZMA Fast (or ZLIB Fast) but if speed is what you want then LZ4 is by far the better choice.
Here is another example but this time the file is a CSV message with 100,000 rows (5.34MB):
~mqm/> ./testcmprsn lrg_msg.csv
testcmprsn version 0.0.1 (Linux64) {Sep 3 2020}
lrg_msg.csv size is 5596526 (5.34MB)
Time taken to perform memcpy() is 2.7790ms
Algorithm Compressed Compression Compression Decompression
Size Time in ms Ratio Time in ms
LZ1 2259971 (2.16MB) 3323.3470 2.48 to 1 13.5200
LZ4 46756 (45.66KB) 1.8300 119.70 to 1 1.5910
LZMA Fast 16135 (15.76KB) 69.0080 346.86 to 1 6.1620
LZMA Best 14292 (13.96KB) 1039.6830 391.58 to 1 6.1660
LZW 875214 (854.70KB) 188.9970 6.39 to 1 51.0490
RLE 11009430 (10.50MB) 12.7800 0.51 to 1 13.7960
ZLIB Fast 1976970 (1.89MB) 62.2680 2.83 to 1 33.9510
ZLIB Best 1417225 (1.35MB) 1205.1500 3.95 to 1 26.6710
testcmprsn is ending.
Again, LZMA Best crushed it. It reduced a 5.34MB file to just 13.96KB (391 fold reduction) but at a cost of 1039.683 milliseconds. A better option for that type of data is to use LZMA Fast but if speed is what you want then LZ4 is by far the better choice.
As a benchmark, the TESTCMPRSN program performs a memcpy() of the data, so that the end-user can compare the compression algorithms compression time against the memcpy() time.
As they say: your mileage will vary. The only way to know which compression algorithm will work best for your data is to test it. Note: RLE should only be used with alphanumeric data (plain text) that has repeating characters and never with binary data.
Beta testing MQ Message Compression is absolutely free including support (no strings attached).
If you interesting in trying it out, please send an email to support@capitalware.com to request a trial of MQ Message Compression.
Regards,
Roger Lacroix
Capitalware Inc.