One thing always leads to another!
In my house (and home office), I had an ASUS RT-AC68U router (on main floor) and a Tenda W150M router (in basement). Once in a while, someone would complain that the ‘internet is not working’ or ‘internet sucks’! Sometimes it would be as simple as being on the wrong router (i.e. being on the main floor but connected to Tenda in the basement). Other times, I would just reboot the router.
A couple of weeks ago, our neighbor, directly across from us, had their SUV stolen in the middle of the night. Cynthia (my wife) said she now wanted a camera in front to cover our drive. We have a Nest doorbell camera but it only shows the view down our side walk to the street.

She found that Best Buy had a 2 pack of Google Nest WiFi outdoor 1080p cameras on sale. So, I went to Best Buy and purchased it. She also signed up for the Google Nest subscription to store the video in the cloud. The next day installed one on each side of the garage. Mounting them wasn’t to difficult but doing the WiFi setup is really slow. I guess it double and triple checks for WiFi signals which takes a very long time.
 |
 |
Kyle setup a PS4 and a 32” monitor on a tray in the family room, so that he could play Fall Guys using WiFi during intermission when we were watching NHL and NBA playoff games. After I added the cameras to the network, he complained that he was losing games because the router was dropping the PS4 connection. And my wife and other kids were complaining about a slow internet.
My ISP allows the customer to have 2 IP addresses. I have an extra router called: CradlePoint MBR95. So, I had the bright idea of putting the CradlePoint router at the front window and running a cable back to the modem and have the 2 Nest cameras and doorbell connect to the CradlePoint router. I offloaded the Nest traffic to a different router, problem solved, so I thought. But it didn’t seem to make a difference. When I logged into CradlePoint router, under WiFi connection, it was showing 50%-70% channel conflict. I tried to manually set the channel to reduce the conflict with the other routers but I could only get it down to 30%. People were still complaining about a slow internet plus the far Nest camera kept going online-offline-online-offline.
I got fed up with it and since I had noticed that ASUS supported a mesh network called AiMesh, I thought why not. I looked at the instructions and it seemed pretty straightforward. If you want an indepth review then read Dong Ngo’s AiMesh Review: Asus’s Ongoing Journey to Excellent Wi-Fi Coverage post.
I decided to use my existing ASUS RT-AC68U router as a node and purchase another ASUS RT-AC68U router to be used as another node. As the primary router, I decided to purchase ASUS RT-AC86U router.
I checked Amazon, Best Buy on pricing and sent an email to Mega Computer (local small retailer). Mega Computer didn’t have ASUS RT-AC86U in stock but had ASUS GT-AC2900 in stock. He offered $20 off to make it the same price as RT-AC86U for $249 CAD (roughly $190 USD) and ASUS RT-AC68U for $179 CAD (roughly $135 USD). So, I bought the items from Mega Computer.
I decided on the following setup: the primary router would be at the very front of the house (main floor), a node at the very back of the house (main floor) and a node in the basement. The ASUS AiMesh can use both wired and wireless for back-hauling. I have partially hard-wired my house with cat 6 Ethernet cable. I have cabling in my office to the server room in the basement and wired the kids game room in the basement. Hence, the node in the basement would use wired backhaul. For the node at the back of the house (kitchen), I decided to run cabling along the baseboards into the kitchen and up on top of the kitchen cabinets. The cabinets don’t go all the way to the ceiling, so I ran the cabling until I ran out of cabinets. The cabinets have a thick top molding, so all you see is 3 little antennas sticking up.
Next, I followed the instructions and upgrade the firmware on all 3 routers. On the primary router (ASUS GT-AC2900), setup the usual stuff: LAN IP address, DHCP server starting and ending range, SSID name for 2.4GHz and SSID name for 5GHz (I use different names i.e. Speedy_2.4 and Speedy_5.0). Make sure everything is setup regardless if you are using the AiMesh or not.
I followed the instructions for resetting the nodes but getting the nodes to be recognized by the primary for AiMesh was impossible. I tried over and over but wasted an hour of my time. I decided to do the setup manually. It is really easy if you have 2 PCs/laptops otherwise you will be doing a lot of cable swapping. Or download the ASUS Router app to your smart phone and use 1 PC.
Next, connect the node to the primary router. Plug the Ethernet cable into a LAN (Yellow or Black) port of the primary router and plug the other end of the cable into the WAN (Blue) port of the node. On your PC log into the node’s administration panel and then click Administration tab and then select AiMesh Node radio button.
You should see the following:
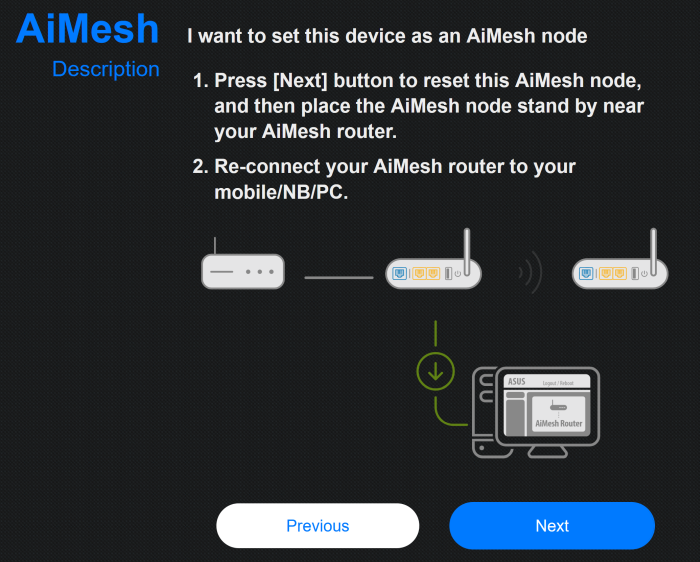
Click the Next button to proceed. And it will begin:
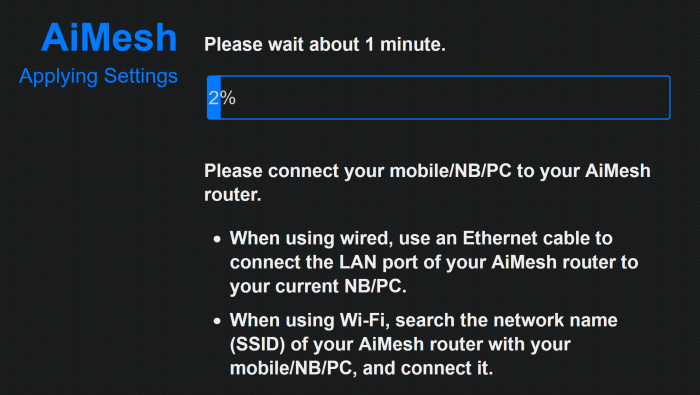
This will take several minutes to complete. You just have to wait it out. When it is done, you will see the following screen:
Now go to your primary router and do the following: click Network Map tab, next click the AiMesh Node icon then click the Search button:
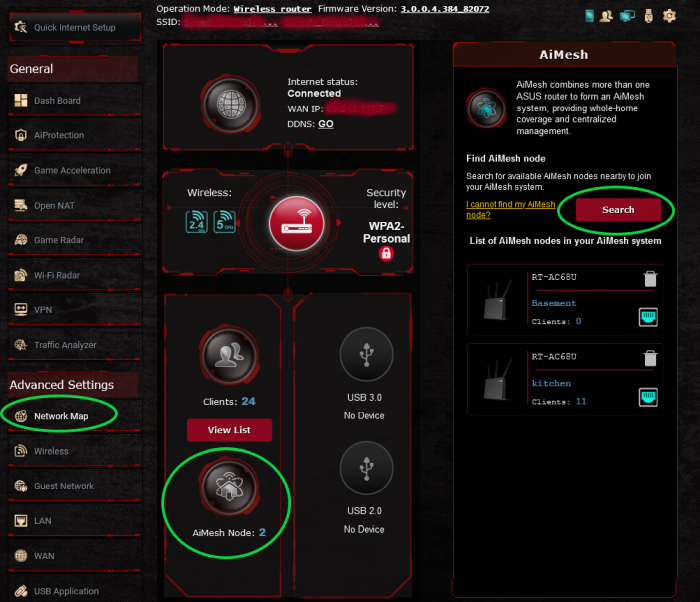
It will popup a window of the found node, simply accept it and you are done. 🙂
The manual process may require 2 PCs/laptops or 1 PC and a smart phone but it is not complicated and works!! If you have more nodes to add, just repeat the process. As you can see, I have 2 nodes. If you click on a node in the list then you can change the name of it and see a list of connected users.
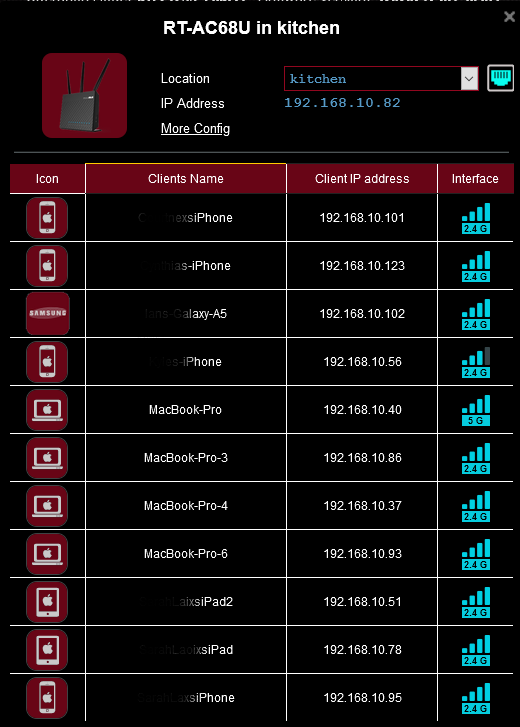
Now people in the house can wander from upstairs to main floor to the basement without switching their WiFi settings on their device. So far, I haven’t heard ‘internet is not working’ or ‘internet sucks’. 🙂
Finally, both the Tenda and CradlePoint routers have been disconnected and put away, as they are no longer needed. In the future, I may add a 3rd node in hallway upstairs but I’ll wait and see if there any complaints about reception in the bedrooms. 🙂
Regards,
Roger Lacroix
Capitalware Inc.